Abstract
We propose 3D Super Resolution (3DSR), a novel 3D Gaussian-splatting-based super-resolution framework that leverages off-the-shelf diffusion-based 2D super-resolution models.
3DSR encourages 3D consistency across views via the use of an explicit 3D Gaussian-splatting-based scene representation.
This makes the proposed 3DSR different from prior work such as image upsampling or the use of video super-resolution, which either don't consider 3D consistency or aim to incorporate 3D consistency implicitly.
Notably, our method enhances visual quality without additional fine-tuning, ensuring spatial coherence within the reconstructed scene.
We evaluate 3DSR on MipNeRF360 and LLFF data, demonstrating that it produces high-resolution results that are visually compelling, while maintaining structural consistency in 3D reconstructions.
Method Overview
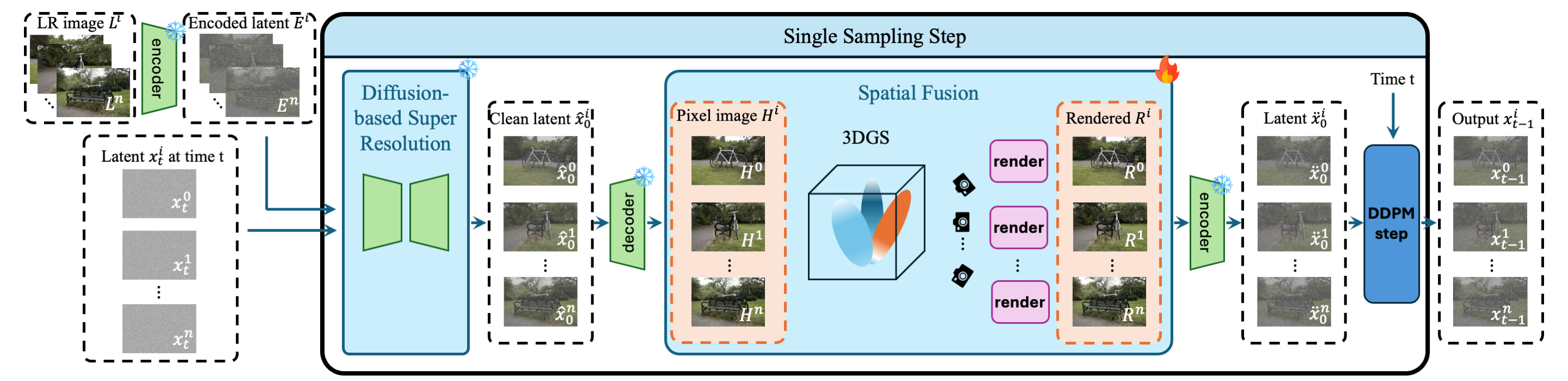
Given a latent x at timestep t, we first estimate the clean image x0 using the denoiser of a pre-trained diffusion model. To enforce 3D consistency, we leverage 3D Gaussian Splatting (3DGS) by treating the predicted clean images as training data. The 3DGS model renders high-resolution, view-consistent images, which are then re-encoded into the latent space to estimate the latent of the next denoising step.